Wordle and data science don’t seem to have much in common. Find out why there’s more than meets the eye. This is the second blog in a three-part series. Read the first part here.
Before we understand how entropy affects Wordle, we need to grasp the basics. What does entropy mean? The dictionary says it is “a way of measuring the amount of order present or absent in a system”.
Entropy as a term has been used in various domains.
- Thermodynamics: entropy is the loss of energy available to do work.
- Data communication: refers to the relative degree of randomness. The higher the entropy, the more frequent are signalling errors.
- Computational linguistics: entropy of a language is a statistical parameter which measures, in a certain sense, how much information is produced on the average for each letter of a text in a language.
- Machine learning: entropy is related to randomness in the information being processed. This is similar to the entropy definition provided for atoms in a system.
- It is also a measure of the number of possible arrangements the atoms in a system can have. In this sense, entropy is a measure of uncertainty or randomness.
To define entropy for this Wordle-related experiment, let us use Shannon’s entropy. Shannon defined entropy in the year 1948. His formula is as below
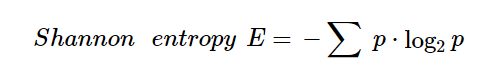
This formula seems complex. Let us break it down into simple structures. We can rewrite it such that the –ve sign is taken into the log formula.
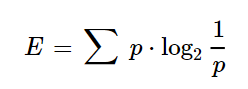
In this approach, the formulas are still complicated.
So, let’s take an example to understand. Consider that there are 3 bags full of plastic balls. They are of mixed colors – red, green, and blue – and are distributed as follows:
- First Bag: 1 red, 2 green and 3 blue
- Second bag: 2 red, 3 green and 1 blue
- Third bag: 2 red, 2 green and 2 blue
I can calculate the probability of choosing the balls from the three bags in a tabular format.
| Bags | Red | Green | Blue |
| First | 1/6 | 1/3 | 1/2 |
| Second | 1/3 | 1/2 | 1/6 |
| Third | 1/3 | 1/3 | 1/3 |
Based on these probabilities, I will be surprised if I get a red ball from the first bag. However, I would be expecting to pick up a blue one, since there is a comparatively higher chance.
Thus, we can say that surprise is inversely proportional to probability.
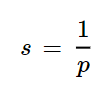
Consider that there is another which has 6 balls, all blue in color. In this case, the probability table will as below
| Bags | Red | Green | Blue |
| First | 1/6 | 1/3 | 1/2 |
| Second | 1/3 | 1/2 | 1/6 |
| Third | 1/3 | 1/3 | 1/3 |
| Fourth | 0 | 0 | 1 |
Here, the probability of selecting a blue ball is 1. If we apply this to the surprise formula, we are expected to have zero or no surprise. However, we see that the value of surprise is also 1. To fix this, let us take the log value of the inverse of probability for surprise.
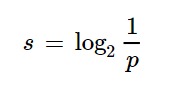
This formula is the second part of the entropy. Hence, in simple terms, we can define entropy as the factor of probability and surprise.
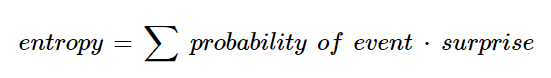
Based on this, let’s compute the surprise value of the three bags
| Red | Green | Blue | |
| First | 2.58 | 1.58 | 1.00 |
| Second | 1.58 | 1.00 | 2.58 |
| Third | 1.58 | 1.58 | 1.58 |
Now, we can compute the entropy of the three bags.
| Entropy | |
| First | 1.46 |
| Second | 1.46 |
| Third | 1.58 |
We see that the entropy of first and second bag is closer to the green and blue respectively. Incidentally, this falls into the middle ground. We intuitively expect the entropy to be closer to the blue and green for first and second bag respectively, as they are in abundance. However, this is not the case. This is because we are pleasantly surprised if we choose a green or blue from bag first or second respectively, as they are the second most abundant in those bags. Hence, the element of surprise is a bit higher.
This term entropy has a greater role to play and has more value in data science. Coming up in part three, I will show how this entropy can be used to solve Wordle.

























