Wordle and data science don’t seem to have much in common. Find out why there’s more than meets the eye. This is the third blog in a three-part series. Read the first and second parts here.
We all know that the English language has 26 characters. Let us consider that each character has an equal likelihood of occurrence in a word (without any bias). Now, we can arrive at the entropy of the English alphabet using the formula
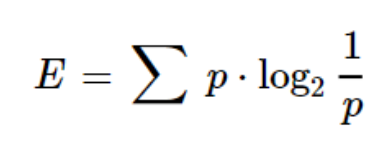
H(x) = 4.7 bits
In this example, H(x) denotes entropy. The unit for entropy is bits. Theoretically, the entropy for English alphabets is 4.11 bits, which is less than the 4.7 bits. I leave it to you, the reader, to research and find out why the entropy is 4.11 bits instead of 4.7. Now, as per the probability distribution of English words, we see that the distribution is not uniform. Based on this, the entropy can be calculated as E = 246.19 bits.
From the previous blog, we noticed that the possibility of occurrence of characters “s”, “c”, “a”, “b” and “t” are higher than the rest. Thus, the entropy now is E = 74.94 bits. We see that the information gain has been phenomenal based on probability. This exercise alone has given us 70% reduction in entropy.
What we have computed here is the entropy of English alphabets for their individual occurrence.
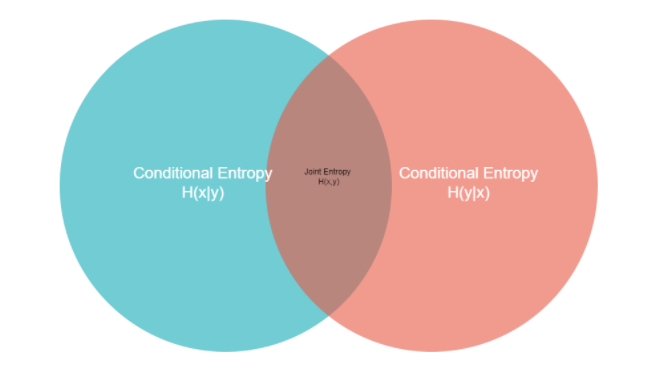
Characters are arranged in a particular order in each word. The occurrence of the next character depends on the earlier character. To measure this, we will need the concept of joint entropy. In simple terms, joint entropy is the measure of uncertainty associated with a set of variables.
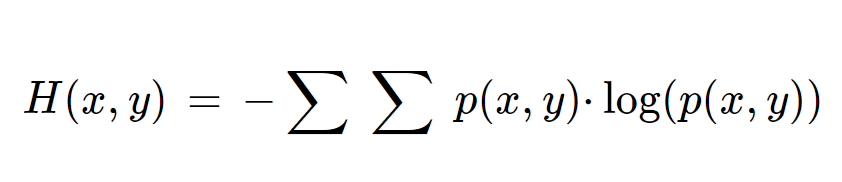
This Venn diagram represents joint entropy.
The table captures the probability of occurrence of a selected pair of letters (c, a), (c, h) and (c, e).
| x | y | P(x,y) | H(x,y) |
| c | a | 0.015643 | 5.9983 |
| c | h | 0.011936 | 6.3885 |
| c | e | 0.003706 | 8.0759 |
Here we see that the statistical dependence between two characters reduces the entropy of the English alphabet.
The entire process of solving Wordle can be converted into an optimization problem. Its objective function: to minimize entropy at each position / stage.
In other words, the Wordle problem is about gaining information through the feedback loop. The game provides 3 kinds of feedback namely Green, Grey and Orange. This information helps in optimizing the entropy, and subsequently selecting the right word. Considering triplets and quadruplets as along with pairs can help in computing entropy very accurately.
This falls into the category of greedy algorithms.
In every step, we want to achieve the maximum drop in entropy. However, it is proven that greedy algorithms may not be optimal. The algorithm selects the letter that has the highest probability of being the first letter. Likewise, the first 3 letters are selected. Every time the search will try to choose the letters having the highest probability, given the feedback/information bits known at that point in time.
In cases where the identified words lies farthest away or least likely to the given word, the iteration would go wrong. As a worst-case scenario, if the word ends being least likely in each step, then the number of iterations required to find the word will be maximum. This can be another problem to solve: how to minimize the number of iterations required to reach the desired word!

























